Predicting Wine Quality via Chemical Profiling
The client, a boutique winery, needed a precise, data-driven method to classify wine quality into three distinct tiers (Low, Medium, and High) based on chemical laboratory measurements. The objective was to eliminate subjective bias and leverage "chemical similarity" to predict how a wine would be rated by experts.
Client
Challenge
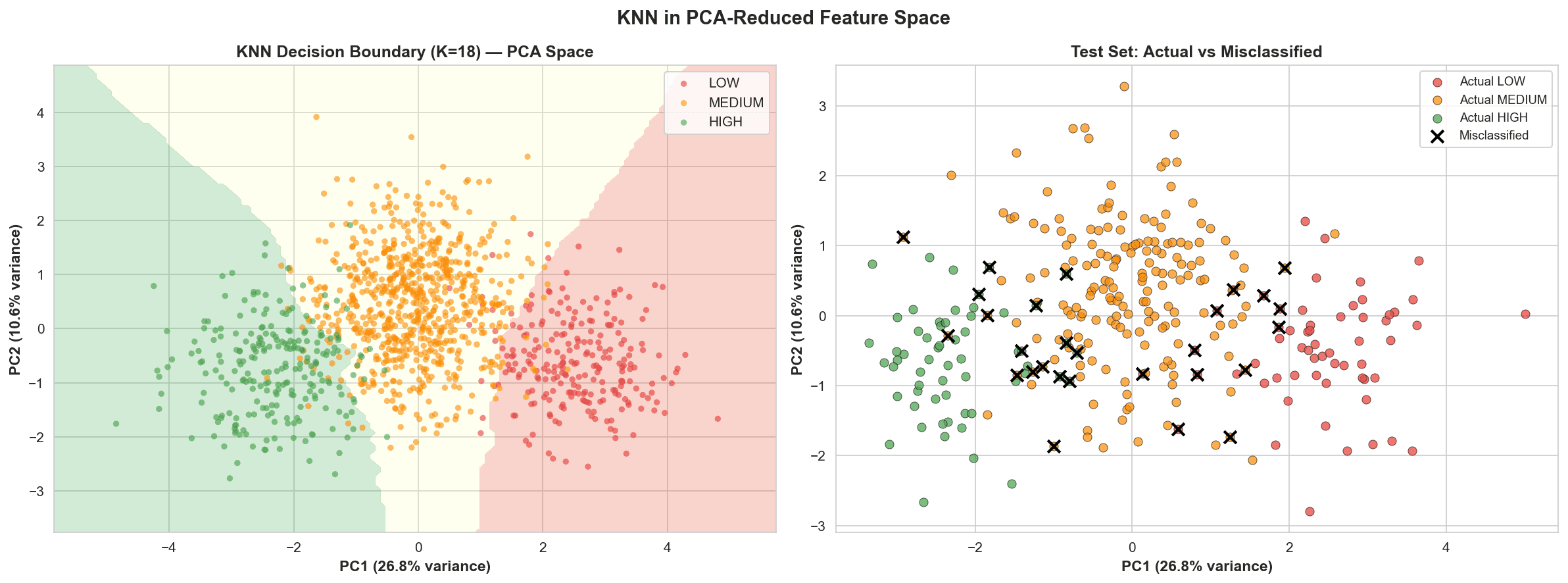
Determining wine quality traditionally relies on expensive, time-consuming sommelier tastings. The client faced several challenges: Subjectivity: Expert ratings can vary, leading to inconsistent product labeling. Complex Interdependence: Wine quality isn't determined by a single factor; it's a non-linear interaction between volatile acidity, alcohol content, and sulphates. * Irregular Decision Boundaries: There is no simple "linear" rule (e.g., more sugar $\neq$ better wine). High-quality wines often share irregular, "local" clusters of chemical properties.
Goal
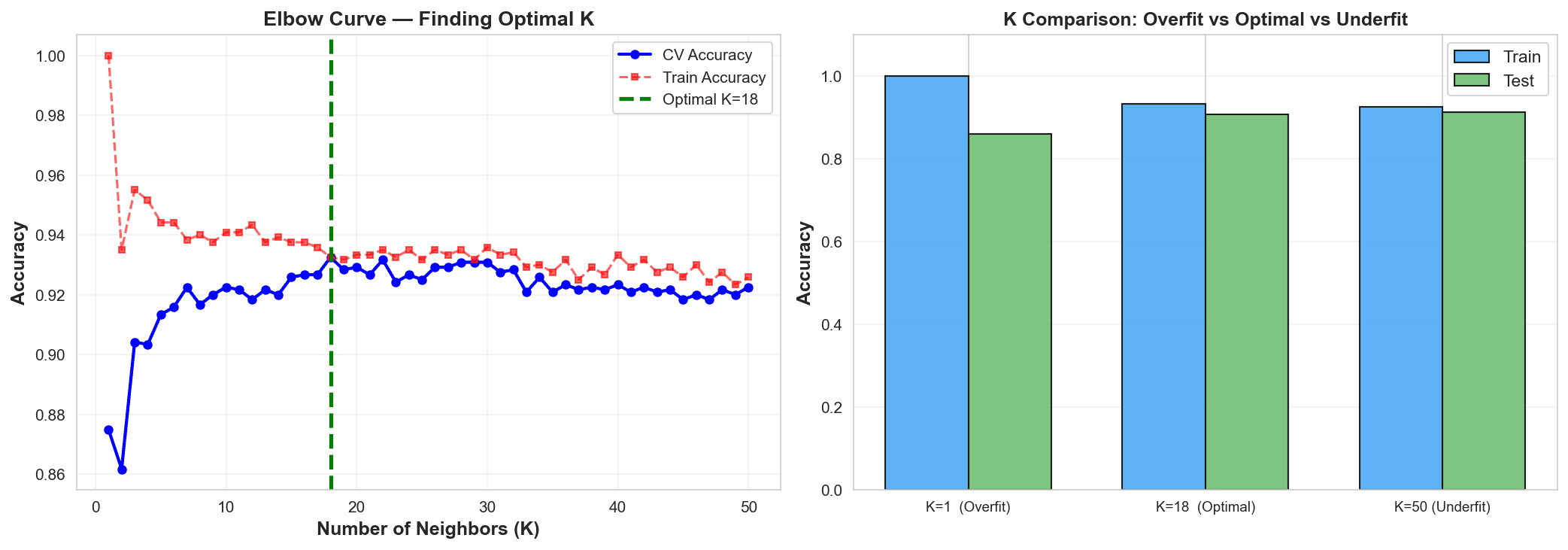
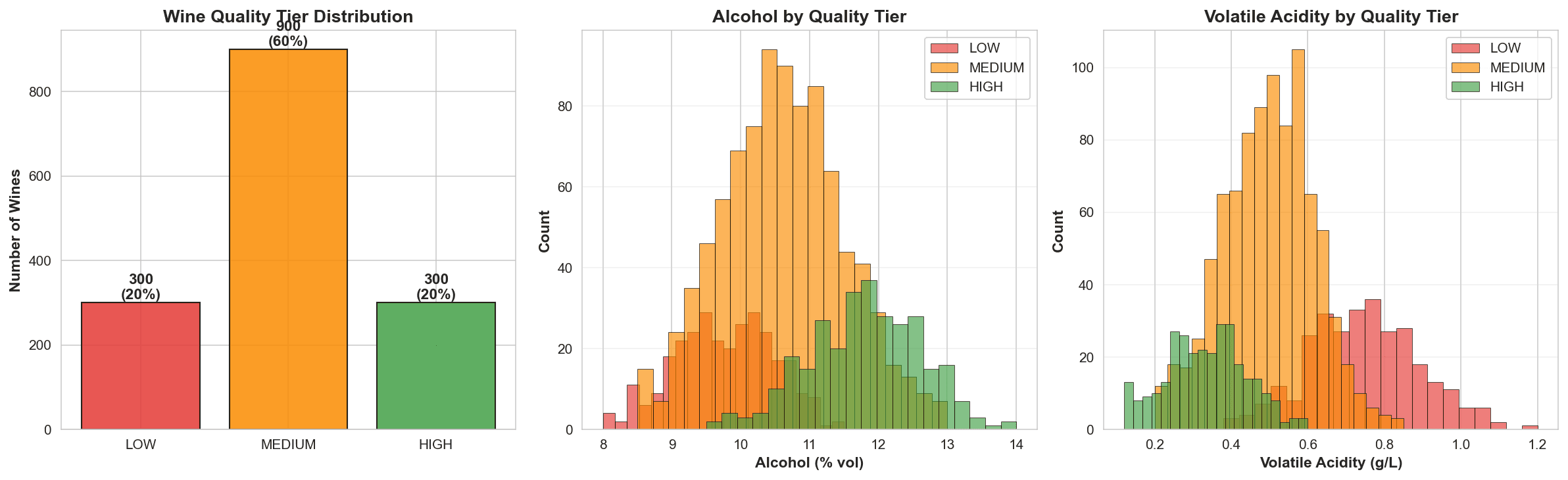
Workflow Overview: Exploratory Data Analysis (EDA): Visualized distributions showing that Higher Alcohol and Lower Volatile Acidity (vinegar-like traits) are strong indicators of the "High" quality tier. Feature Standardization: Since KNN relies on Euclidean distance, I used StandardScaler to ensure that features like Total Sulfur Dioxide (mg/L) didn't mathematically overwhelm features like pH or Density. Hyperparameter Optimization (The Elbow Method): Ran a recursive loop testing $K$ values from 1 to 50. Identified Optimal $K=18$ to balance the model—preventing it from being too sensitive to noise (low $K$) or too generalized (high $K$). Confidence Mapping: Generated a probability distribution to identify which "Medium" wines were borderline "High," allowing the client to refine their blending process.
Result
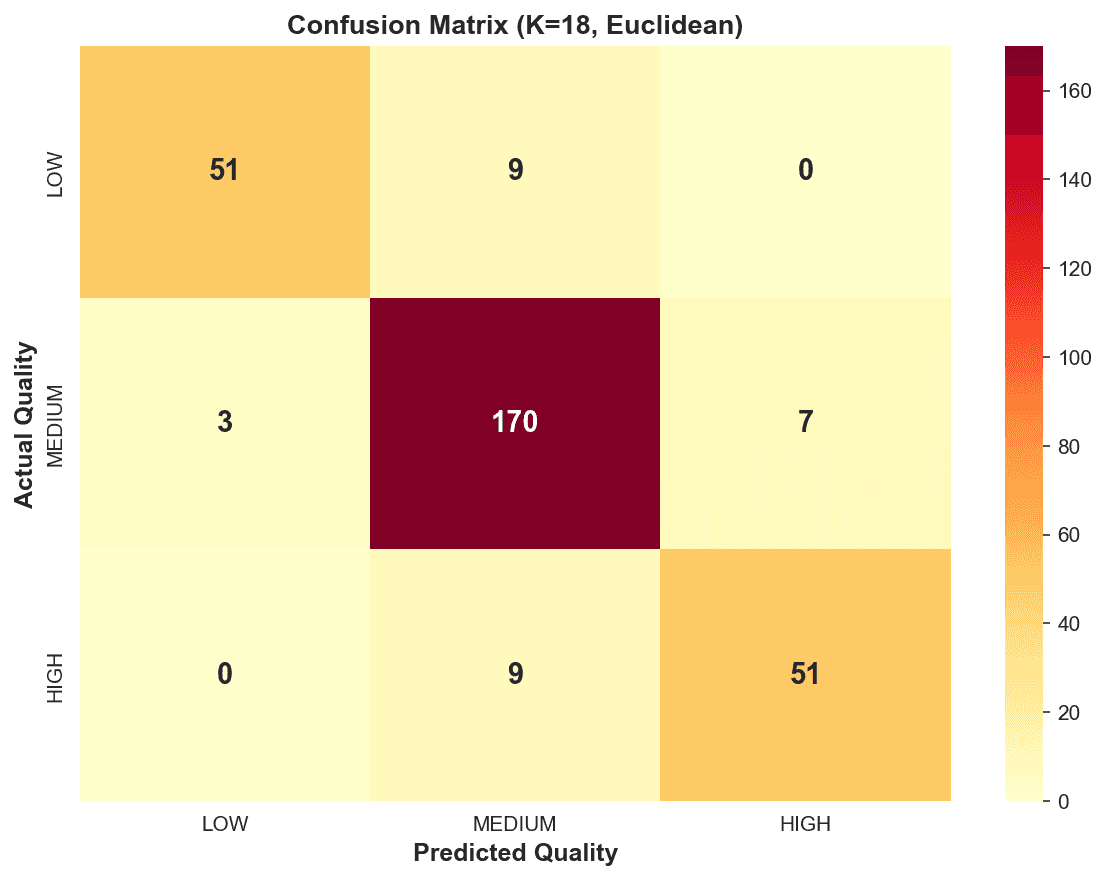
The model proved that chemical "neighborhoods" are highly accurate predictors of taste: Optimal Accuracy: Achieved a 93.2% Cross-Validation Accuracy at $K=18$. * High Precision: The model correctly identified 170 out of 180 Medium-tier wines in the test set, with near-zero confusion between "Low" and "High" tiers. Confidence Insights: Analysis showed that most "Correct" predictions had a confidence score $>0.9$, while "Wrong" predictions were clustered in the 0.5–0.6 range, signaling "borderline" chemical profiles. Zero-Training Latency: As a "lazy learner," the model required no lengthy training phase, allowing for instant classification as new lab results arrive.